Manual Image Segmentation in Computer Vision: A Comprehensive Overview of Annotation Techniques

This blog post provides a comprehensive overview of three primary methods of manual image segmentation in Computer Vision: Overlaying, Snap to Object Boundaries and Split Mask.

Table of Contents
Introduction
Manual image segmentation might seem like a straightforward and dull task. However, challenges arise when dealing with complex images. For instance, images with crossings objects requiring annotation, distinct parts of a single object, or numerous neighboring objects in a scene. This overview explores three main strategies: Layering, Snapping, and Splitting. Each strategy brings specific advantages for particular segmentation needs. We will compare all three methods on identical livestock images to better illustrate their differences. It is worth noting that these methods are used in a variety of industries: medical, agriculture, manufacturing, energy, transportation, retail, construction and many other domains.
Method 1: Layering
The Layering method, sometimes referred to as object overlap or bottom-up order in machine learning community and academia, is used for annotating images by systematically layering annotations on top of each other based on predetermined priorities. In most cases the annotation starts with the farthest objects from the camera and finishes with the closest objects that are layered on top of the previous.
It stands out as a highly effective and widely used technique in high-quality, dense pixel annotation projects, exemplified by the Cityscapes Dataset. Within the Layering technique, each object within an image is annotated to guarantee the correct overlap, adhering to a set sequence in line with the annotator's script and compliant labeling policy. This leads to the creation of an accurate Semantic or Instance Segmentation mask for every image, where each pixel is classified according to the object type it represents. Such a multi-layered approach is crucial for developing detailed and comprehensive segmentation maps.
The Cityscapes project, specifically, utilized the Layering to accurately label urban scenes. It involved the manual creation of polygons around each object, corresponding to various classes like roads, trees, cars, pedestrians and buildings. This labor-intensive method resulted in high-quality data, which is indispensable for training advanced Computer Vision algorithms, especially in Semantic Segmentation tasks.
A notable aspect of the Layering method is its efficiency, making it arguably the quickest among all annotation techniques. This efficiency stems from two key factors:
- the ability to simultaneously use diverse shapes such as polygons, masks, or bounding boxes for annotation
- the leniency in precision for the underneath layers as subsequent layers will eventually refine and neaten the overlaps. This results in clean and precise masks after the annotations are rasterized.
 Use of different object shapes with Layering technique for manual annotation of cows
Use of different object shapes with Layering technique for manual annotation of cows
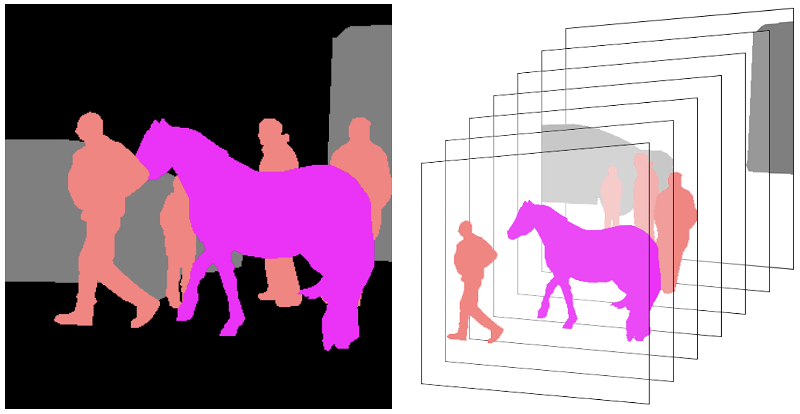 Priority of layers from farthest to nearest
Priority of layers from farthest to nearest
When to Use Layering?
Complex Scenes: As demonstrated in the Cityscapes project, Layering method excels in annotating complex urban environments where multiple objects overlap or exist in close proximity. This includes streets with various elements like vehicles, pedestrians, signage, and buildings. This also includes agricultural and manufacturing scenarios.
Semantic Segmentation Tasks: When detailed pixel-level segmentation and classification is required, such as in Semantic Segmentation, this method is ideal. It allows to do precise delineation of each object, ensuring that each pixel is correctly classified.
Large-Scale Image Datasets: For projects that require the annotation of vast numbers of images, this method can increase efficiency. Its ability to handle multiple shapes (like polygons and masks) and layers simultaneously speeds up the annotation process while maintaining quality.
Scenarios Demanding Layered Annotations: In cases where objects in an image are layered or obscured by other objects, approach to layering annotations ensures that even partially hidden objects are accurately labeled.
Flexible Annotation Requirements: The method's ability to use and easy editing various shapes like polygons, masks, or bounding boxes makes it versatile for different types of objects and scenarios. Also it works perfectly in projects, where the annotation requirements can change over time, for example when new object classes are added to annotation guidelines or labeling requirements for specific objects are changed and the existing annotation has to be corrected.
Projects with Iterative Refinement Needs: The Layering method allows for initial rough annotations to be refined in subsequent layers, making it suitable for projects where iterative refinement is part of the workflow.
Layering annotation method requires postprocessing to finalize the annotations. For effective neural network training, it is necessary to use all classes of data in their entirety, without excluding any annotations from the training process. If it is necessary to exclude overlapping data, specialized post-processing applications that automatically remove such overlaps should be used.

Rasterize objects on images
Convert classes to bitmap and rasterize objects without intersections
Method 2: Snapping
The Snapping method, also known as Snap To Boundaries, is a less widely used approach for manual annotation. This method is distinct in its arrangement of objects: they are required to touch each other but must not overlap. A key challenge in using Snapping is the precision needed to connect the boundaries of each object in an image. To ease this process, the Supervisely team introduced a feature that automatically connects adjacent points and allows to use existing points to label the object contour, significantly simplifying the task.
A crucial problem of this method is its difficulty in labeling intricate scenes. Editing one object often necessitates adjustments to all adjacent objects. Similarly, when an object is removed or its boundary is modified, the gap must be filled using the existing objects, thus all neighboring objects have to be modified as well which is time consuming and leeds to annotation ineffeciency. Despite this, Snapping can be efficient and convenient for simpler tasks, such as labeling scenes with a few zones and objects or individual components of objects.
 Masks of cows created using the Snapping annotation technique
Masks of cows created using the Snapping annotation technique
When to Use Snapping?
Simple Scenes with Few Objects: Snapping works best in simpler scenes where there are only a few neighboring objects or zones to label. Its straightforward approach to connecting adjacent points makes it efficient for such tasks.
Projects Requiring Precise Boundaries: Snapping method is ideal for images where precise delineation of object boundaries is critical. Since objects must touch each other, but not overlap, it ensures clear separation. However, this can also be achieved by other methods.
Educational Purposes: Given its straightforward approach, Snapping can be an excellent tool for teaching basic principles of image annotation.
Disadvantages: Not suitable for scenes with many overlapping objects or where changes to one object might necessitate numerous adjustments to others. In such cases, a more advanced annotation tool might be required to handle the complexity efficiently. Also, the labeling process can become much more complicated if the annotation requirements change, for example, if the list of annotation classes is adjusted or if already labeled objects need to be edited.
Method 3: Splitting
The Splitting annotation method, also known as the Split Mask, streamlines the annotation of complex objects and scenes by segmenting a mask into smaller, more manageable pieces. This approach is exclusively applicable to masks, facilitating their integration with neural network outputs that similarly utilize masks. It provides users with unifying masks that are modifiable using a variety of tools, including brush, pen and eraser, as well as with a polygon to fine-tune the boundaries or create holes in the mask. The Split Mask method is particularly adept at splitting objects into their components and is easy to use in the annotation process. It doesn't require you to keep track of the labeling sequence and frees you from post-processing. With just one tool, annotators can efficiently label both simple and difficult-shaped objects, making the splitting method both user-friendly and highly effective. This method would be perfect for such a popular dataset as ADE20K.
The ADE20K dataset comprises a vast collection of images sourced from diverse environments, encompassing a range of scenes and objects. Each image within this dataset undergoes meticulous detailed manual annotation. Annotators break down each object into its parts. For instance, in annotating a car, distinct elements like wheels, windows, and doors are individually highlighted. This granular approach to annotation is pivotal for training and testing machine learning models, particularly for tasks in Semantic Segmentation. Models trained on the ADE20K dataset learn to recognize not just whole objects but their individual components, significantly enhancing the precision and depth of the scene.
 Masks of parts of cows created using the Splitting annotation technique
Masks of parts of cows created using the Splitting annotation technique
When To Use Splitting?
Complex Scenes with High Detail: When dealing with images that contain intricate details or numerous small components, Splitting method allows for more accurate and detailed annotation. By breaking down a complex image into smaller segments, it becomes easier to focus on and annotate individual elements.
Labeling Objects With Holes: When annotating objects that contain holes or internal voids, the Splitting method comes in handy. It allows for separate annotation of the object's external boundaries and its internal spaces, ensuring that models can accurately recognize them. This is particularly important for objects where the presence of holes significantly affects their identification and classification.
Training Advanced Deep Learning Models: For deep learning models, especially those involved in computer vision tasks like semantic segmentation, this method provides detailed training data without the need in additional postprocessing steps, because the resulting annotaiton is presented in the form of non-overlapping masks. It helps these models learn to recognize and differentiate between various parts of an object, leading to more precise and nuanced understanding.
Scenes with Overlapping Objects: In images where objects overlap or are closely situated, the Splitting method helps in accurately distinguishing and annotating each object without confusion.
To summarize, the Splitting method is best used in scenarios that demand high precision and detail in image annotation, especially where individual components within an image play a crucial role in the overall interpretation and usage of the data.
Disadvantage: can only be used with mask shape.
Comparison table: Analyzing Methods
| Features/Method | Layering | Snapping | Splitting |
|---|---|---|---|
| Shape |
Any shape |
Polygons |
Masks |
| Creating |
The bottom layers may not be labeled accurately |
Maximum precision labeling |
It may be inaccurate at intersections with other objects |
| Object Editing/Deletion |
Easy |
Require adjustemt of other objects |
Creates gaps needing fill-ins |
| Combining Different Shapes |
Seamless integration of shapes like polygons and masks |
Careful integration required, especially for mask to polygon conversion |
Not possible |
| Prelabeling |
Neural Networks/Ensemble of Neural Networks/Smart Tool |
- |
Neural Networks/Smart Tool |
| Benchmark Prevalence |
Cityscapes |
Not commonly used |
Not commonly used |
| Labeling Organization |
Allows for specialized annotation teams |
Requires versatile annotators across multiple object classes |
Increasing workload to one person and potential for mistakes |
Neural Network predictions
We recommend to approach the task of image segmentation in a variety of ways, often moving from manual annotation methods to automated, highly accurate prediction models. These models can interpret and segment images at the pixel level, beyond the limitations of manual methods in terms of speed, scale and accuracy. This section delves into different neural network approaches for prelabeling, focusing on various strategies such as the use of Smart Tool, Single Neural Networks, Ensembles of Neural Networks and other approaches to improve prediction performance.
All segmentation models produces predictions in a form of segmentation masks. That is why Supervisely Image Annotation tool supports by default annotation with masks (brush tool), polygons and combination of both (pen tool). If manual annotation is combining with the interactive ML-assisted annotation and classical model prelabeling then the necessity of combining different annotation tools on a single image becomes crucial.
Also it is important to directly work with the masks instead of converting them to polygons because this transformation leads to decrease in annotation quality on object boundaries due to contour approximation. We recommend to use "layering" approach in such scenarios. It will allow you to combine polygons and masks during annotation and gives you flexibility to use various annotation instruments (polygon, brush, pen) in combination to increase the efficiency.
Smart Tool
Smart Tool, powered by artificial intelligence (AI), can automatically identify and segment objects within an image. The Smart Tool offers users access to a wide variety of neural network algorithms for the task of object segmentation, integrated within Supervisely. This includes powerful models such as Segment Anything, Segment Anything HQ, RITM, and others. For instance, in the case of Layering, Smart Tool can recognize even objects overlapped by other annotations. This prelabeling significantly reduces manual effort by providing an initial layering of objects, which annotators can refine as needed.

RITM interactive segmentation SmartTool
State-of-the art object segmentation model in Labeling Interface

Serve Segment Anything Model
Deploy model as REST API service
Single Neural Network Model
Image Segmentation Neural Networks, such as well-known U-Net or any state of the art model from MMSegmentation toolbox, predict segmentation masks for the every class. These masks indicate the presence of different classes of objects by assigning each pixel in the image to a specific class. The approach is similar to a "Split method" where the output is a set of non-overlapping masks representing different components or objects on the image. This ensures clarity in identifying different objects without their intersection.

Train UNet
Dashboard to configure, start and monitor training

Train MMSegmentation
Dashboard to configure, start and monitor training
Single Model Limitations: When using a single neural network model for segmentation, the process tends to be binary or multi-class but without the capability for complex interactions between object classes, such as Overlapping or Snapping scenarios. The model predictions are usually exclusive, meaning a pixel can belong to only one class, leading to a clear separation or Splitting of object classes without overlaps. This simplifies segmentation but limits the ability to handle complex scenarios where objects might naturally overlap or where a hierarchical relationship might exist.
Ensemble of Neural Networks
It is quite often scenario when you have multiple custom models for different set of classes instead of having single model that can segment all object of interest at once. And in some industrial use cases it is more beneficial to have an ensemble of separate models for different classes. There are few reasons for that:
-
You have separate training datasets for different subset of classes.
-
You do not have the requirement for real-time processing.
-
You want to improve models separately.
-
You change labeling requirements (add or remove classes) over time and do not want to retrain your models.
By employing an ensemble of models, or a multi-stage neural network pipelines, it becomes possible to introduce a form of Layering where different models specialize in recognizing different layers of an image. This can address the limitations of single models by allowing for more complicated interpretations of the image data, such as recognizing overlapping objects or distinguishing between closely related classes (like a car and its defects).
Consider, for example, the task of segmenting a road surface and segmenting defects such as potholes or cracks. If the model is trained to recognize only the road, a pothole will be considered as a part of the road. In such a case, it is necessary to have another model for segmenting potholes on top of the road. This case is perfectly covered by "Layering" approach. You will be able to combine predictions from model ensemble with the manual annotation to segment complex dense scenes.
Another example is the annotation of cars, their parts and defects using different models. When you prepare the training data for such use case you need to annotate an entire car and defects on top of it (layering). It is crucial to consider that you will use subsample of classes to train neural network for defects; and train separate car segmentation model using the cars masks without holes. The most efficient annotation approach for that is also Layering.
Example of road surface segmentation illustrates a common challenge: when an object (the road) incorporates objects that could be considered as separate classes (potholes), a single-model approach might struggle to distinguish these without specific logic to handle such cases (having the hierarchical relations of road mask and its potholes). Post-processing, in this context, involves merging the model output masks to achieve a coherent final result that accurately represents the real-world scene.
Similarly, for car defect detection, a neural network might identify both the car and its defects as distinct classes. Without a strategy to integrate these classes, the final output might inaccurately represent the relationship between the car and its defects. The solution requires a combination of outputs (car and defect masks) to create a unified, accurate representation of the object and its condition.
These challenges highlight the importance of selecting the right model pipeline for your task and using the appropriate annotation strategy for building the accurate training data for it.
Conclusion and Summary
This blog post explains the three main methods of manual image segmentation in Computer Vision: Layering, Snapping (Snap to Object Boundaries), and Splitting (Split Mask). Each method has its own advantages and is best suited for certain types of segmentation tasks.
-
Layering is ideal for scenarios where it is important to distinguish and separate multiple overlapping objects, thanks to the principle of prioritizing the overlapping of layers on top of each other.
-
Snapping uses advanced tools to automate the process and is best suited for tasks where you need to clearly connect elements without overlapping.
-
Splitting allows you to cut out different parts of an object, making the new objects from them.
The choice of segmentation method depends on the annotation properties. If accuracy and flexibility in working with overlapping objects are important, Layering is preferable. For tasks that require clear separation without overlapping, Snapping and Splitting methods are suitable. If detailing of objects is required, Splitting is the best. It is also possible to combine these methods to achieve optimal results.
It is important to choose the annotation strategy carefully, as a wrong choice can lead to inefficient consequences such as increased annotation time or decreased data quality. The key is to understand the specifics of the task and apply the most appropriate annotation method accordingly.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



