Segment Anything 2 (SAM2) in Supervisely: The Fast and Accurate Object Segmentation Tool for Image and Video Labeling

How to automatically segment and track objects on images and videos using Segment Anything model 2 in Supervisely

Table of Contents
In this tutorial, you'll learn how to use Segment Anything 2 for quick and precise object annotation of images and videos in the Supervisely Platform.
The initial release of Segment Anything received great acclaim, earning an Honorable Mention at ICCV 2023 and attracting the attention of both industry leaders and the academic community. Building on this success, Meta has now introduced Segment Anything 2, which improves the precision of image segmentation and extends its functionality to video recognition. In this guide, we explore the new features of Segment Anything 2, that integrated seamlessly into the Supervisely Ecosystem. Now all Supervisely users can easily use SAM2 in their Computer Vision pipelines.
Video Tutorial
In this step-by-step video guide, you will learn how to use The Segment Anything Model 2 to efficiently annotate your images in Supervisely.
You’ll discover:
-
How to create annotation classes and segment objects via providing feedback to SAM2 by putting bounding boxes and refining object segmentation with positive and negative clicks.
-
How this class-agnostic model can help segment objects from different domains and industries, and be used to annotate detailed objects composed of many parts.
-
How to freely use the SAM2 model, which is deployed by default for all users with no additional setup required, and explore deployment options for Pro and Enterprise users, including customizing model weights for specific tasks.
What is Segment Anything 2?
Segment Anything Model 2 (SAM 2) is a foundation model for interactive instance segmentation in images and videos. It is based on transformer architecture with streaming memory for real-time video processing. SAM 2 is a generalization of the first version of SAM to the video domain, it processes video frame-by-frame and uses a memory attention module to attend to the previous memories of the target object. When SAM 2 is applied to images, the memory is empty and the model behaves like usual SAM.
SAM 2 vs SAM 1
Unlike the first version of Segment Anything, the frame embedding used by the SAM 2 decoder is conditioned on memories of past predictions and prompted frames (instead of being taken directly from an image decoder). Memory encoder creates "memories" of frames based on the current prediction, these "memories" are stored in model's memory bank for use in subsequent frames. The memory attention operation takes the per-frame embedding from the image encoder and conditions it on the memory bank to produce an embedding that is then passed to the mask decoder.
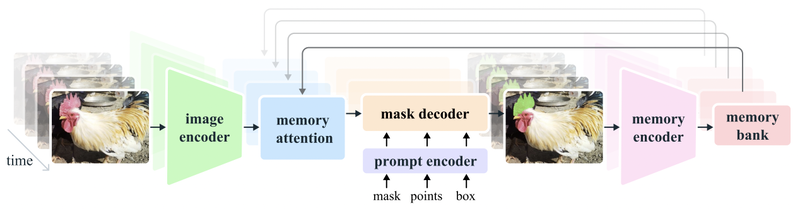 SAM 2 architecture
SAM 2 architecture
Segment Anything 2 key features
Image encoder
Segment Anything 2 uses Hiera pretrained hierarchical image encoder — hierarchical structure allows using multiscale features during decoding. Image encoder is used only once for the entire interaction to get feature embeddings representing each frame.
Prompt encoder and mask decoder
SAM 2 prompt encoder is identical to prompt encoder of the first version of SAM. Mask decoder is similar to the first version of SAM, but has some specific features. The first version of SAM assumed that there is always a valid object to segment given a positive prompt, but new version of SAM supports also promptable video segmentation task — and in this task target object can be not present on some frames. To handle such corner cases an additional head was added to predict whether the target object is present on the current frame or not. New mask decoder also uses skip connections from hierarchical image encoder — it is necessary for getting high-resolution information for mask decoding.
Memory encoder
Memory encoder down samples output masks with the help of convolutional module and sums it element-wise with frame embedding from image encoder. Lightweight convolutional layers are used for information fusion.
Memory bank
Memory bank is used to store information about previous predictions for target object. Memory bank employs FIFO (first-in-first-out) queue of memories up to N recent frames and M prompted frames — both sets of memories are stored in a form of spatial feature maps. In addition to these spatial feature maps, memory bank also stores a list of object pointers — lightweight vectors for high-level semantic representation of objects to be segmented. These vectors are produced based on mask decoder output tokens of each frame.
Memory attention
Memory attention is used to produce current frame features based on the features of previous frames plus new prompts. Several transformer blocks are stacked, the first block takes encoding of current frame as an input, each block performs self-attention in combination with cross-attention to memories of frames, stored in a memory bank, followed by MLP.
Training
Segment Anything 2 was trained jointly on image and video data. Interactive prompting simulation was organized the following way: sample sequences of 8 frames, randomly select up to 2 frames to prompt and probabilistically receive corrective clicks (these clicks were sampled using ground truth masklet and model predictions during training). There were several variants of initial prompts: ground truth mask with 50% probability, a positive click (sampled from ground truth mask) with 25% probability and a bounding box with 25% probability.
Dataset
Segment Anything 2 was trained on SA-V dataset — it contains ~51K videos with ~643K masklets. It was split into training, validation and test sets based on the video authors and their geographic location to guarantee minimal overlap of similar objects. Meta's internal dataset (~63K videos) was used for training set augmentation.
Segment Anything 2 performance analysis
Promptable video object segmentation
Promptable video object segmentation assumes generation of masks for initial frame and tracking of these masks on the rest of the frames.
For this task, authors of SAM 2 had two modes: offline evaluation, where multiple passes are made through a video to select frames to interact with based on the largest model error, and online evaluation, where the frames are annotated in a single forward pass through the video. These evaluations were conducted on 9 zero-shot video datasets using 3 clicks per frame.
Previous approaches for promptable video object segmentation usually required using several models: one model for initial frame labeling and another one for masks tracking. Good examples of such tandem are SAM + XMem++ and SAM + Cutie. Segment Anything 2 outperforms both of these combinations while being able to both create masks on initial frame and track them on the rest of the frames:
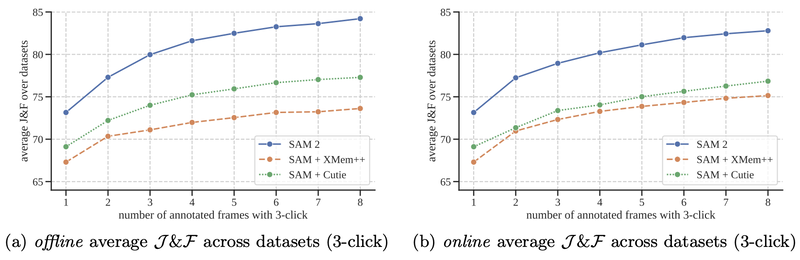 SAM 2 promptable video object segmentation
SAM 2 promptable video object segmentation
Semi-supervised video object segmentation
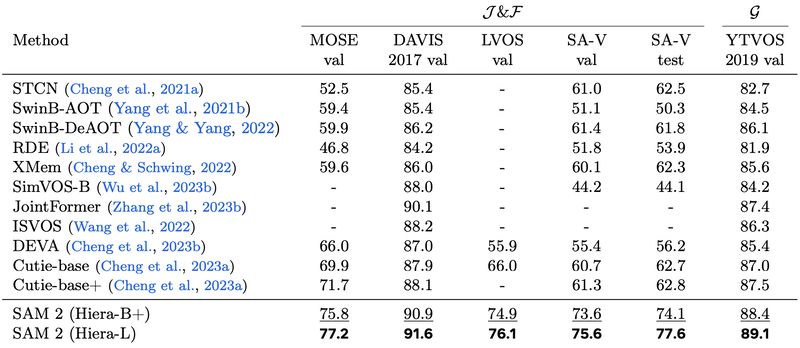
Semi-supervised video object segmentation assumes usage of existing box, click or mask prompts only on initial frame of the sequence and tracking of segmentations on the rest of sequence. Authors of SAM 2 used click prompts, interactively sampled either 1, 3 or 5 clicks on the first video frame and then tracked the object based on these clicks.
Segment Anything 2 outperforms preexisting methods for this task:
 SAM 2 semi-supervised video object segmentation
SAM 2 semi-supervised video object segmentation
Another variation of semi-supervised video object segmentation assumes usage of ground truth mask on the first frame as a prompt. SAM 2 demonstrates significantly better performance than existing approaches:
 SAM 2 semi-supervised video object segmentation
SAM 2 semi-supervised video object segmentation
Image tasks
SAM 2 was evaluated on the Segment Anything task using 37 zero-shot datasets (23 of these datasets were previously used by SAM for evaluation).
SAM 2 achieves higher accuracy (58.9 mIoU with 1 click) than SAM (58.1 mIoU with 1 click), without using any extra data and while being 6 times faster. According to authors of SAM 2, it can be mainly attributed to the smaller but more effective Hiera image encoder in SAM 2.
 SAM 2 image tasks
SAM 2 image tasks
Overall, the findings underscore SAM 2’s dual capability in interactive video and image segmentation, a strength derived from diverse training data that encompasses videos and static images across visual domains.
How to use SAM 2 in Supervisely
The Segment Anything Model 2 (SAM2) is available to all Community Users by default and is deployed in Supervisely Cloud. You can follow these steps to use the SAM2 model on the Supervisely Computer Vision Platform:
1. Segment objects on images
Usage of Segment Anything 2 as a Smart Tool for image labeling. Just open annotation toolbox, select the Smart Tool instrument for object segmentation, put bounding box around the object of interest and correct the model's predictions with positive and negative clicks:
2. Video object segmentation and tracking
To perform video object segmentation and tracking, you need to segment object in the first frame and then press the Track button in the timeline. Make sure that you are using the SAM2 model and have configured the number of frames for tracking.
3. Automatic image mask generation
Generate automatic image masks without any prompts via NN Image Labeling app. Run the app inside the annotation toolbox, connect to the SAM2 model and press Apply model button to get the predictions. Then, use the right mouse button to assign the correct classes to automatically segmented objects.
You can also apply the model to an object in bounding box. This is a way to get prediction only within a specific region of interest on the image:
4. Batched Object Segmentation
Fast labeling of images batch via Batched Smart Tool app. If you have bounding boxes around your objects, you can use this app to apply SAM in a batched manner, speeding up the annotation of all objects in your training dataset. The SAM2 model will be applied to every object in your dataset, and you can refine the model's predictions if the object segmentation is not precise enough.
How to deploy SAM 2 on your own GPU
Enterprise and Community Pro users can run the model on their own GPUs:
Step 1. Connect your GPU
In Supervisely it is easy to connect your own GPU to the platform and then use it to run any Neural Networks on it for free. To connect your computer with GPU, please watch these videos for MacOS, Ubuntu, any Unix OS or Windows.
Step 2. Run the corresponding app to deploy SAM 2 model
Select the pretrained model architecture, press the Serve button and wait for the model to deploy.
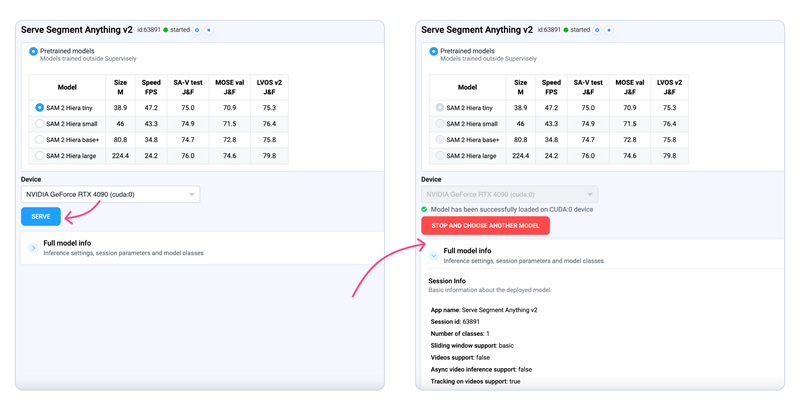
Now you can use your own SAM2 model in image and video object segmentation. Check our the steps above.
Conclusion
Supervisely Ecosystem provides modern ways of labeling any type of data for Computer Vision, including both images and videos. In this tutorial we learned how to perform image and video object segmentation and tracking using state-of-the-art SAM 2 neural network in Supervisely.
SAM 2 will be an excellent choice for improving the speed and quality of data labeling both for images and videos. Sign up and try to label your data for free in Community Edition.
Supervisely for Computer Vision
Supervisely is online and on-premise platform that helps researchers and companies to build computer vision solutions. We cover the entire development pipeline: from data labeling of images, videos and 3D to model training.
The big difference from other products is that Supervisely is built like an OS with countless Supervisely Apps — interactive web-tools running in your browser, yet powered by Python. This allows to integrate all those awesome open-source machine learning tools and neural networks, enhance them with user interface and let everyone run them with a single click.
You can order a demo or try it yourself for free on our Community Edition — no credit card needed!
Liked this blog post? Share it!





Subscribe to new blog posts
Table of Contents
🤖 Try Supervisely: it's free!
Full stack platform with hundreds of Apps ready to solve any computer vision task: from labeling to model training. Create account



